
NBA Basketball
Lakers 1.95
Celtics 1.95
Cloudbet automation · BYOK · paper-first
Connect your own Cloudbet account, define the markets and staking rules, and start in paper mode before any live bet is allowed. Funds stay with Cloudbet. Glitch Edge only automates the strategy you approve.
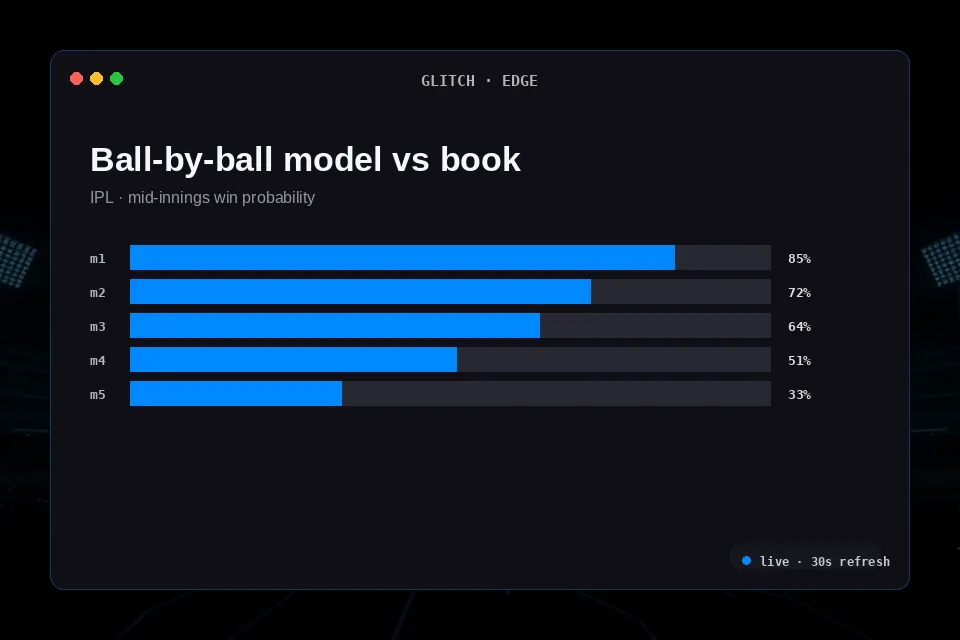
Example markets · representative odds
A sample of the kinds of markets your strategy can match against. Glitch Edge does not pick winners or sell signals — it evaluates your rules against the live Cloudbet feed every 60 seconds.
Numbers above are illustrative and not tied to any current event. The live integration pulls upstream market data once per build and displays it without recommendation. Your strategy reads Cloudbet's own feed directly through your API key.
Or skip the licensing call — run it yourself
The same engine, packaged as a hosted platform. Build rules (sport, market, odds range, stake sizing), connect your Cloudbet account, and the worker places bets while you sleep — paper-only until you flip the switch. You own the funds; we never custody them.
Create a Cloudbet account via the button below. Deposit €10+ to self-serve your API key.
Paste it once. We encrypt it with AES-256-GCM at rest and never show it again. You can revoke at any time.
Match → filter → sizing. Start in paper mode. Promote to live when the numbers earn it. Hard bankroll + stake caps you set.
Sports betting carries real financial risk. Glitch Edge is software you instruct; it never guarantees a return. Restricted jurisdictions apply (see Cloudbet's terms). Bet responsibly — and only what you can afford to lose.
What automation should enforce
Glitch Edge is built for bettors who already have a thesis and want controlled execution. The platform starts in paper mode, keeps funds at Cloudbet, and makes bankroll caps a server-side rule instead of a note in your spreadsheet.
connect your own account; Glitch Edge never custodies customer money
same rule engine, simulated ledger, no bet sent to the sportsbook
worker rejects actions that breach the bankroll rules you configured
strategy edits, key access, paper bets, live attempts, and settlements
What you license
Cricket and NBA models share a common state abstraction and pricing core, so every upgrade on one side compounds across both. You run the tools inside your own infrastructure. The software produces outputs; your desk decides which, if any, to act on.
IPL and PSL match-state model you run on your own feed. Emits win-probability, CRR projection, and scenario distributions per delivery. Your desk reads the output and decides what, if anything, to back.
Pregame and in-game fair prices for sides, totals, and props, conditioned on lineup, rest, travel, and injury priors. Pull the output into your own pricing sheet; your traders decide the size.
Composable primitives for fair-price conversion, Kelly fractions, and bankroll-aware sizing. The tools compute suggested sizes from your risk parameters; the operator confirms or overrides every one.
Every model ships with a harness that lets your desk shadow-trade it against historical and live feeds before any live stakes are considered. The tool never graduates itself — promotion to live is always an operator decision.
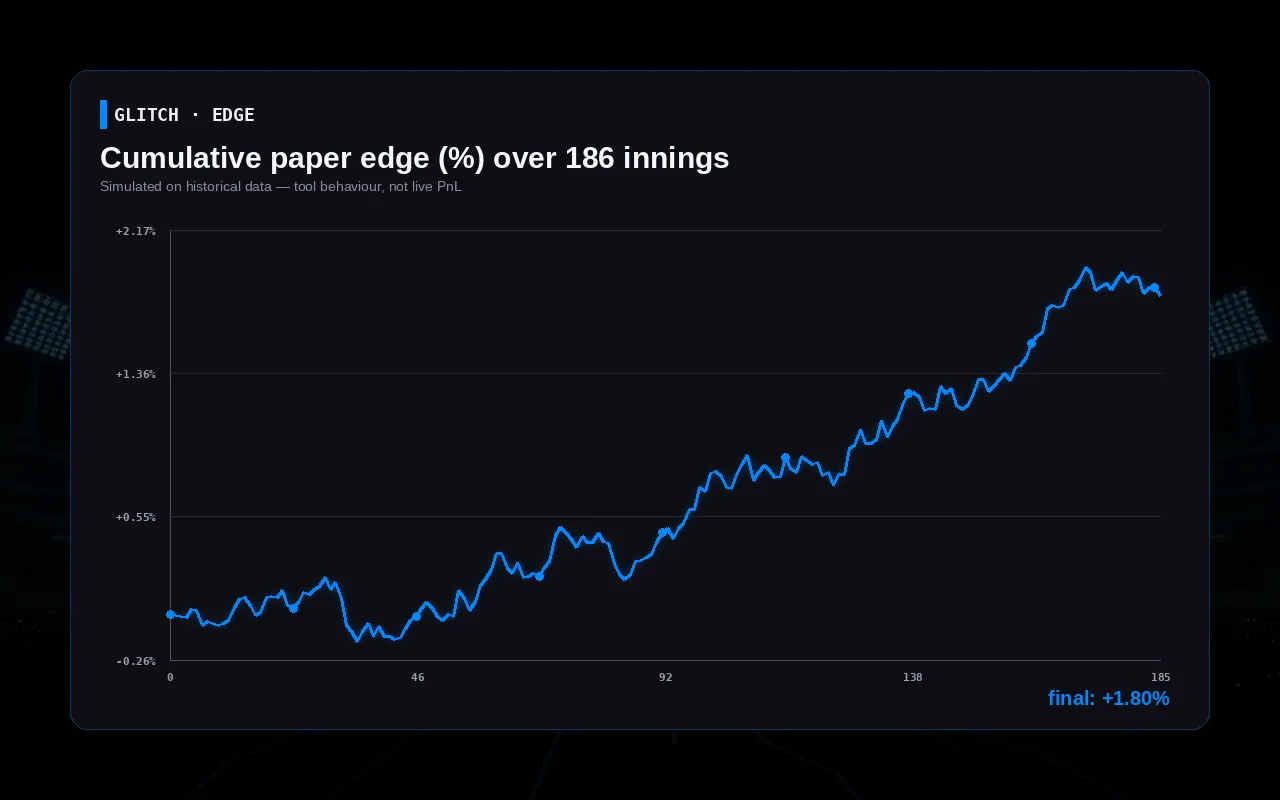
Case spotlight · backtest, not live PnL
The cricket model was backtested ball-by-ball over 186 IPL innings against mid-innings book pricing under fixed staking parameters. Mean absolute error landed at 0.41 rpo; simulated staking on fair-price deviation produced roughly +1.8% paper edge in that window. These are tool outputs on historical data — not a prediction of the PnL any operator will see when they license the model and run it against live matches on their own book.
30-day pilot · fixed scope
No six-month retainers, no "sports AI roadmap" PDFs. One scoped pilot, one tool metric, one number at the end. If the software didn't move it, you didn't pay. The refund is on tool behaviour — it is never a guarantee about the wagers you choose to place.
Read-access to the data feeds you already run (Cricsheet/exchange, NBA API, odds feeds). Within five business days you get one report: how the cricket or NBA model behaves on an event window you pick, which tool output moves the biggest number against your existing baseline, and the single metric the pilot will target.
Cricket model, NBA model, or a slice of both — deployed inside your own infra, emitting outputs into a shadow environment you control. The harness runs paper-first with sample + Sharpe gates your desk configures. The tools never place bets; any move from paper to live is an operator decision.
We compare the target metric (paper edge vs close, MAE, CLV, ball-to-output latency — whichever we scoped) against the Day-0 baseline. The tools produced a signal above threshold? You license Phase 2 month-to-month, no retainer trap. No signal above threshold? Pilot fee refunded in full, no questions. The refund is on tool behaviour — it is never tied to your live betting PnL.
Pilot fee quoted on the first call after we see your data setup. No NDA required to scope.
FAQ
No hype, no implied returns. Glitch Edge automates rules you configure; the safety work is making those rules visible, capped, and reversible.
Under the hood
Open-source primitives for pricing and staking, proprietary ML for the signal, self-hosted data inside your infrastructure where the moat lives. No black-box "signals service", no SaaS that owns your edge — the tools run on your hardware and the operator drives the book.
Talk to us
We reply within one business day. If it's urgent, email us directly — support@glitchexecutor.com.